Prompt Once, Segment Everything: Leveraging SAM 2 Potential for Infinite Medical Image Segmentation with a Single Prompt
Resumen
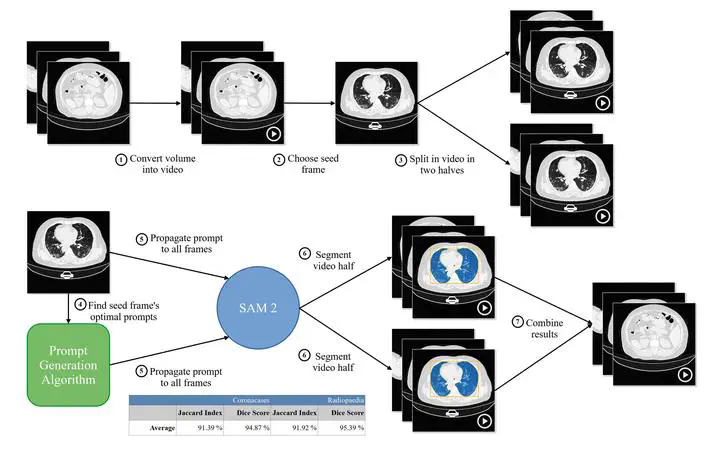
La segmentación semántica de imágenes médicas encierra un gran potencial para mejorar los procedimientos diagnósticos y quirúrgicos. Los especialistas en radiología pueden beneficiarse de herramientas de segmentación automatizada que facilitan la identificación y el aislamiento de regiones de interés en las exploraciones médicas. Sin embargo, para obtener resultados precisos, es necesario desarrollar y entrenar sofisticados modelos de Deep Learning adaptados a esta tarea específica, una capacidad no accesible universalmente. SAM 2 es un modelo fundacional diseñado para tareas de segmentación de imágenes y vídeos, construido sobre la base de su predecesor, SAM. Este artículo presenta un enfoque novedoso que aprovecha las capacidades de segmentación de vídeo de SAM 2 para reducir el número de prompts necesarios para segmentar un volumen entero de imágenes médicas. El estudio compara en primer lugar el rendimiento de SAM y SAM 2 en la segmentación de imágenes médicas. Se utilizan métricas de evaluación como el Jaccard Index y el Dice Score para medir la precisión y la calidad de la segmentación. A continuación, se presenta nuestro novedoso enfoque. Las pruebas estadísticas incluyen la comparación de las ganancias de precisión y la eficiencia computacional, centrándose en la compensación entre el uso de recursos y el tiempo de segmentación. Los resultados muestran que SAM 2 consigue una mejora media del 1,76 % en el Jaccard Index y del 1,49 % en el Dice Score en comparación con SAM, aunque con un aumento de diez veces en el tiempo de segmentación. Nuestro novedoso enfoque de la segmentación reduce en un 99,95 % el número de prompts necesarios para segmentar un volumen de imágenes médicas. Demostramos que es posible segmentar todos los cortes de un volumen y, aún más, de todo un conjunto de datos, con un único prompt, logrando resultados comparables a los obtenidos por los modelos más avanzados entrenados explícitamente para esta tarea. Nuestro planteamiento simplifica el proceso de segmentación, lo que permite a los especialistas dedicar más tiempo a otras tareas. Los requisitos de hardware y personal para obtener estos resultados son mucho menores que los necesarios para entrenar un modelo de Deep Learning desde cero o para modificar el comportamiento de uno existente mediante técnicas de modificación de modelos.
Juan D. Gutiérrez
Profesor Ayudante Doctor
Profesor Ayudante Doctor en la Universidade de Santiago de Compostela. Me gusta la informática pero, sobre todo, aprender cosas nuevas.
Emilio Delgado
Investigador
Carlos Breuer
Investigador
José M. Conejero
Profesor titular
Profesor titular de la Universidad de Extremadura. Mis intereses de investigación incluyen el desarrollo dirigido por modelos, la ciencia de los datos y el aprendizaje automático.
Roberto Rodriguez-Echeverria
Profesor titular
Profesor titular en la Universidad de Extremadura. Software passionate, Deep learner, MTB rider and father of 2.