 Simulated weights of a medium-sized town
Simulated weights of a medium-sized town
Resumen
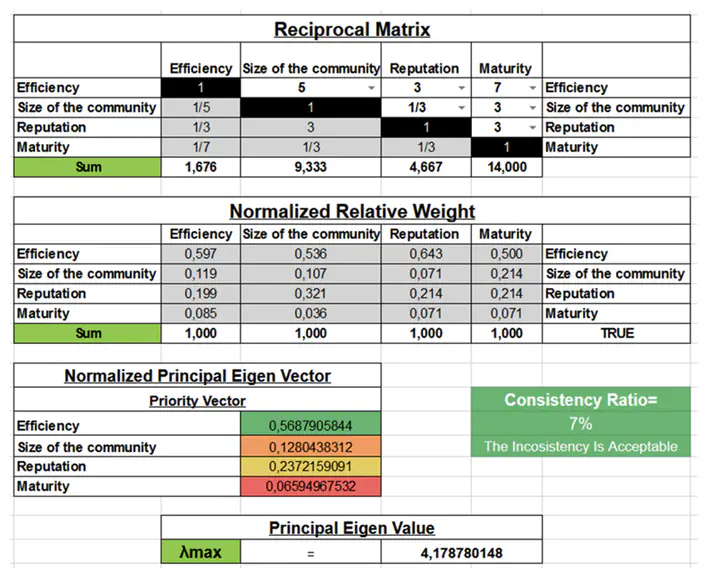
Publishing and maintaining open data is a costly task for public institutions, that becomes even more challenging in the context of Smart Cities, where large amounts of varied data are generated from different domains. To optimize resources, they should prioritize the publication and maintenance of datasets most likely to generate social and economic impact. However, there is currently a lack of decision-support tools to help public sector data publishers to evaluate datasets on the light of their particular reuse goals. In this paper, we propose to suggest to data publishers the dataset categories with most potential impact, based on the impact of already published datasets of the same category. To measure impact, we propose a set of indicators based on the amount and quality of Open Source Software projects that use datasets. To aggregate indicators according to specific reuse goals, we provide an Analytic-Hierarchy-Process based tool.
Alvaro E. Prieto
Profesor Titular
Profesor Titular y Director de Administración Electrónica en la Universidad de Extremadura.