No More Training: SAM's Zero-Shot Transfer Capabilities for Cost-Efficient Medical Image Segmentation
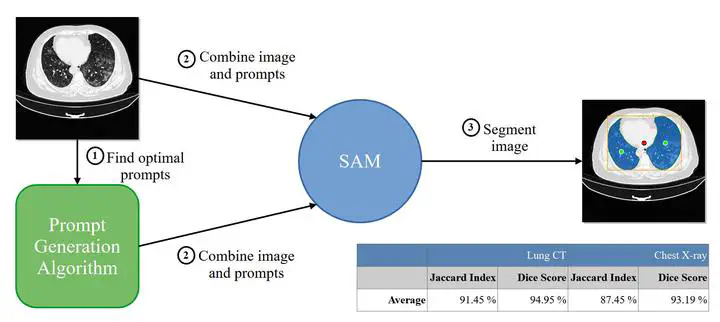 Graphical Abstract
Graphical Abstract
Abstract
Semantic segmentation of medical images presents an enormous potential for diagnosis and surgery. However, achieving precise results involves designing and training complex Deep Learning (DL) models specifically for this task, which is only available to some. Segment Anything Model (SAM) is a model developed by Meta capable of segmenting objects present in virtually any type of image. This paper showcases SAM’s robustness and exceptional performance in medical image segmentation, even in the absence of direct training on these image types (lung Computed Tomographies (CTs) and chest X-rays, in particular). Additionally, it achieves this impressive outcome while requiring minimal user intervention. Although the dataset used to train SAM does not contain a single sample of both medical image types, processing a popular dataset comprised of 20 volumes with a total of 3520 slices using the ViTL version of the model yields an average Jaccard index of 91.45 % and an average Dice score of 94.95 %. The same version of the model achieves a 93.19 % Dice score and a 87.45 % Jaccard index when segmenting a frequently-used chest X-ray dataset. The values obtained are above the 70 % mark recommended in the literature, and close to state-of-the art models developed specifically for medical segmentation. These results are achieved without user interaction by providing the model with positive prompts based on the masks of the dataset used and a negative prompt located in the center of bounding box that contains the masks.
Juan D. Gutiérrez
Assistant Professor
Assistant Professor at Universidade de Santiago de Compostela. I enjoy computing but, above all, learning new things.
Roberto Rodriguez-Echeverria
Associate Professor
Associate Professor at Universidad de Extremadura. Deep learner, MTB rider and father of 2.
Emilio Delgado
Researcher
Fernando Sánchez-Figueroa
Full Professor
My research focuses on Web engineering, big data visualization, and MDD.