Beyond Spectrograms: Rethinking Audio Classification from EnCodec's Latent Space
Abstract
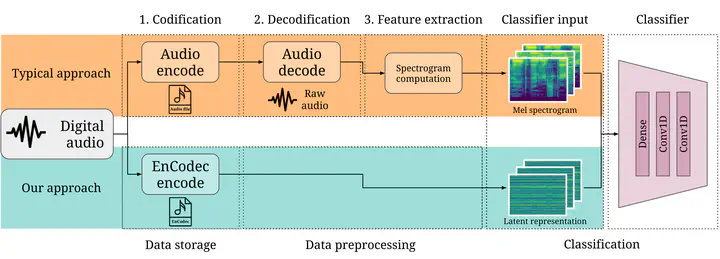
This paper presents a novel approach to audio classification leveraging the latent representation generated by Meta’s EnCodec neural audio codec. We hypothesize that the compressed latent space representation captures essential audio features more suitable for classification tasks than the traditional spectrogram-based approaches. We train a vanilla convolutional neural network for music genre, speech/music, and environmental sound classification using EnCodec’s encoder output as input to validate this. Then, we compare its performance training with the same network using a spectrogram-based representation as input. Our experiments demonstrate that this approach achieves comparable accuracy to state-of-the-art methods while exhibiting significantly faster convergence and reduced computational load during training. These findings suggest the potential of EnCodec’s latent representation for efficient, faster, and less expensive audio classification applications. We analyze the characteristics of EnCodec’s output and compare its performance against traditional spectrogram-based approaches, providing insights into this novel approach’s advantages.
Jorge Perianez-Pascual
Researcher
Software engineer and reasearcher at i3lab. Co-founder of MetrikaMedia.
Juan D. Gutiérrez
Assistant Professor
Assistant Professor at Universidade de Santiago de Compostela. I enjoy computing but, above all, learning new things.
Roberto Rodriguez-Echeverria
Associate Professor
Associate Professor at Universidad de Extremadura. Deep learner, MTB rider and father of 2.