A Model-Driven Approach for Systematic Reproducibility and Replicability of Data Science Projects
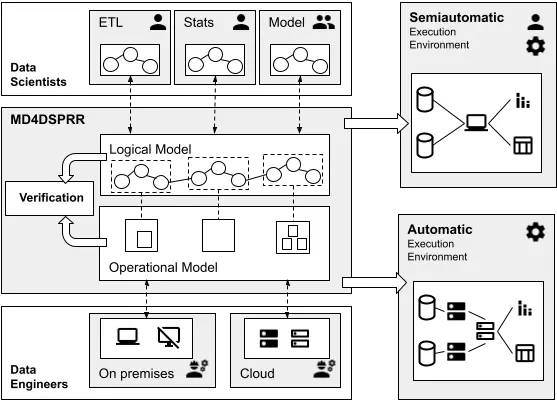 MD4DSPRR Overview
MD4DSPRR Overview
Abstract
In the last few years, there has been an important increase in the number of tools and approaches to define pipelines that allow the development of data science projects. They allow not only the pipeline definition but also the code generation needed to execute the project providing an easy way to carry out the projects even for non-expert users. However, there are still some challenges that these tools do not address yet, e.g. the possibility of executing pipelines defined by using different tools or execute them in different environments (reproducibility and replicability) or models validation and verification by identifying inconsistent operations (intentionality). In order to alleviate these problems, this paper presents a Model-Driven framework for the definition of data science pipelines independent of the particular execution platform and tools. The framework relies on the separation of the pipeline definition into two different modelling layers: conceptual, where the data scientist may specify all the data and models operations to be carried out by the pipeline; operational, where the data engineer may describe the execution environment details where the operations (defined in the conceptual part) will be implemented. Based on this abstract definition and layers separation, the approach allows: the usage of different tools improving, thus, process replicability; the automation of the process execution, enhancing process reproducibility; and the definition of model verification rules, providing intentionality restrictions.
Fran Melchor
Researcher
Roberto Rodriguez-Echeverria
Associate Professor
Associate Professor at Universidad de Extremadura. Deep learner, MTB rider and father of 2.
José M. Conejero
Associate Professor
Assistant Professor at Universidad de Extremadura. My research interests include Model-Driven Development, Data Science, Machine Learning.
Alvaro E. Prieto
Associate Professor
Associate Professor and Director of E-Administration at the University of Extremadura.
Juan D. Gutiérrez
Assistant Professor
Assistant Professor at Universidad de Extremadura. I enjoy computing but, above all, learning new things.